
Overthinking the Draft
Thoughts and Wine about the Draftology

Today is the day where the lives of 32 teenagers will change. The Draft is one of the few special moments in the hockey year where everyone gets to see each other. From media people, to hockey operation personnel, to fans, to agents, the Draft really reunites everyone in a same place.
For nerds like me, it is the opportunity to show the product of weeks and months of work. This one Draft is special. I got to work on TheDraftDigest with Chace McCallum and Josh Khalfin for the past 2 years. Those 2 people are some of the smartest people I have ever talked to and I feel really lucky to had the chance to meet them and build things with them. For those who don’t know about, TheDraftDigest is a tool using Data Science method to assess hockey prospects. Unfortunately, we had to shutdown the Shiny App we created… but it was for a good reason : Chace made it to the NHL. I don’t think there is someone more deserving than him.
So I gave myself the challenge of re-building the website. I can’t say I succeeded because I don’t have a fully working website ready for people to use, but I don’t arrive empty-handed. I built a variety of tools to support prospect assessments.
League strength
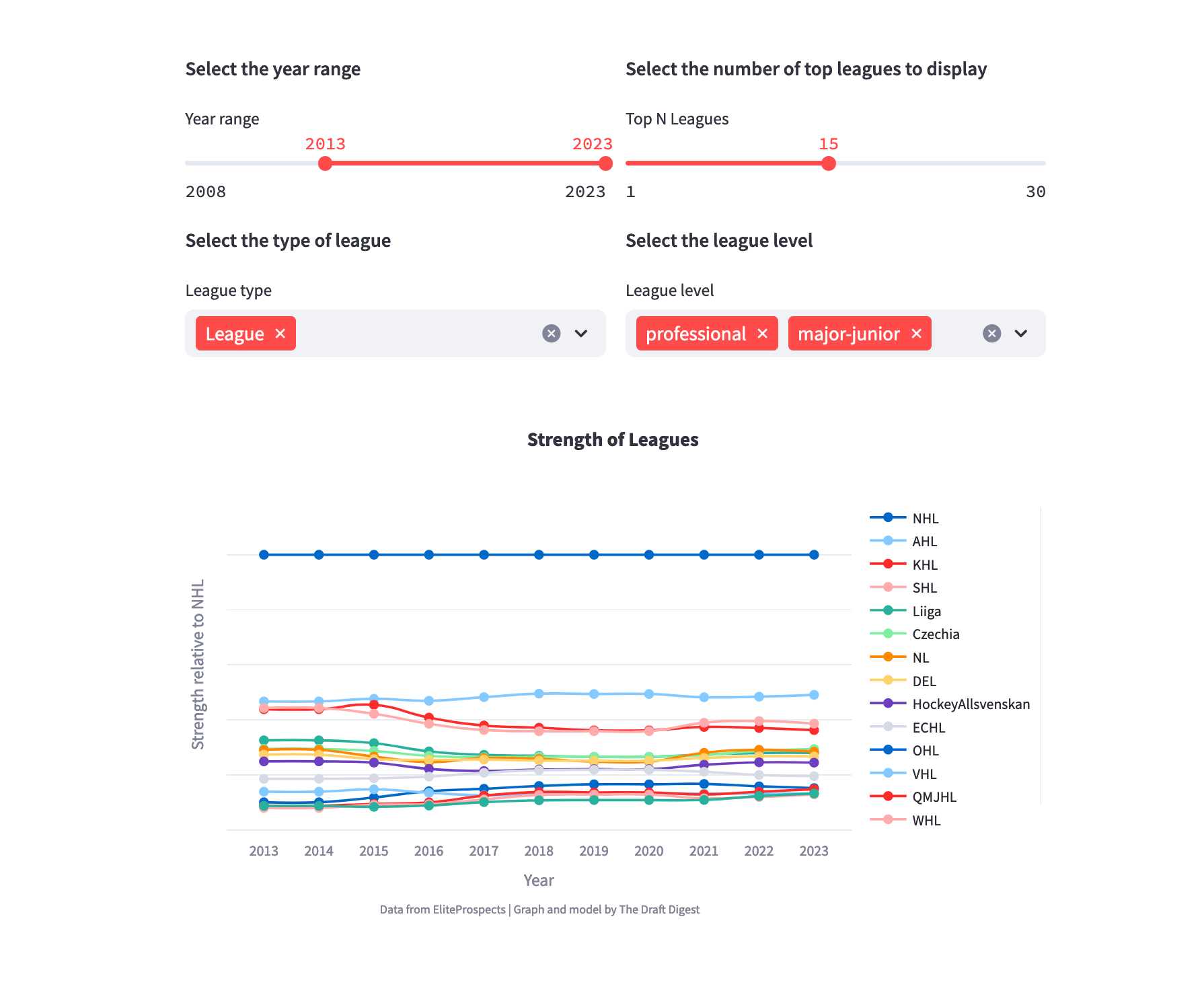
This one screenshot of the strength of leagues shows an iteration of my estimation of the strength of the best 15 leagues in hockey. I think the lates To come up with those numbers, I used a method inspired by Katerina Wu (now Pittsburgh Penguins) in her work “Which League is the Best?” that she presented at the CBJHAC2018. She used transition matrix and difference in points-per-game for players changing leagues within a season or in the following the season. Then, she used a OLS model to estimate league strength. To see the league strength per year, I just iterated the process per season.
NHLe has its limitations, but I think it is a decent indicator of league strength.
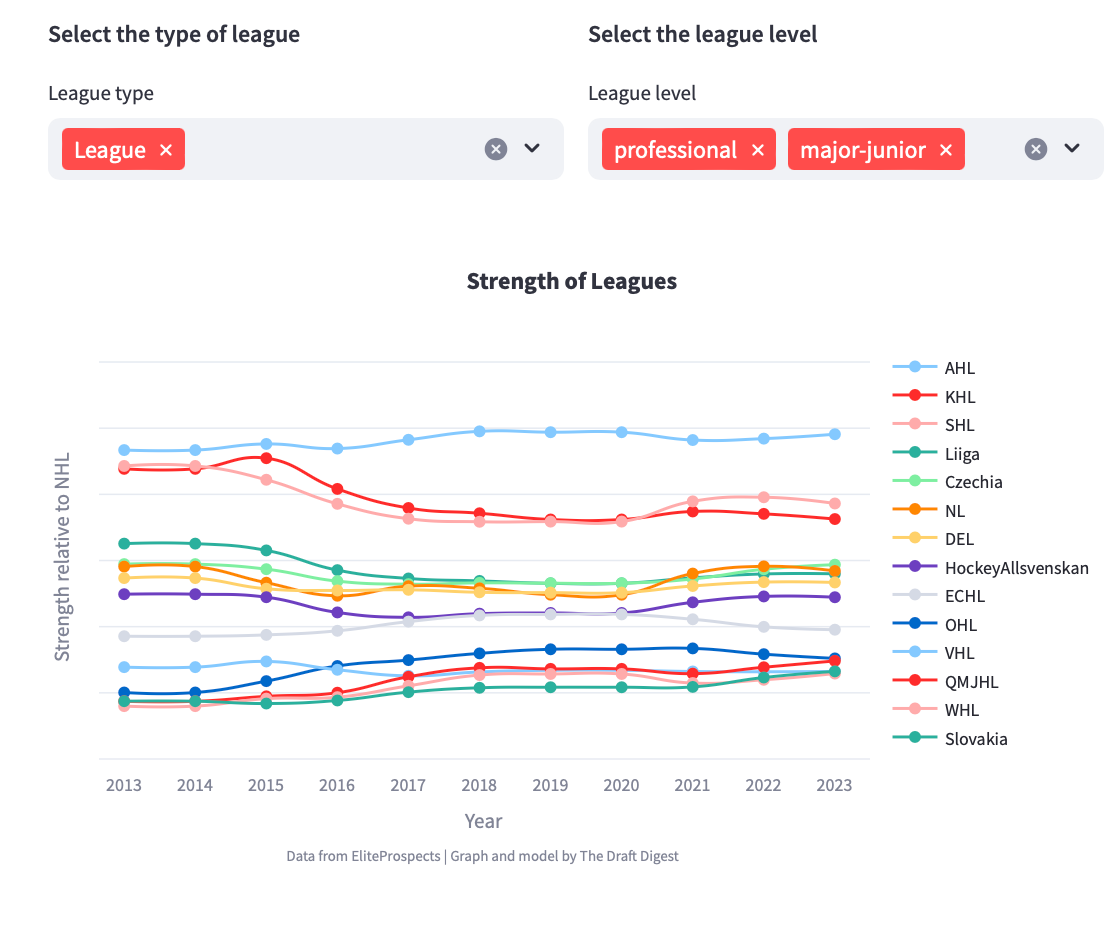
If we forget about the NHL and the fact that all league seems to be the same strength and we use a different scale, we see a different story. Chace was the first person I know to notice that the KHL was losing its power in term of 2nd best league in the world while the AHL should be taken more seriously as a difficult leagues. All of the iterations of my model have shown this trend. Unfortunately, this viz does not have 2024, but I can confirm that no league is challenging the NHL yet.
Player ranking tools
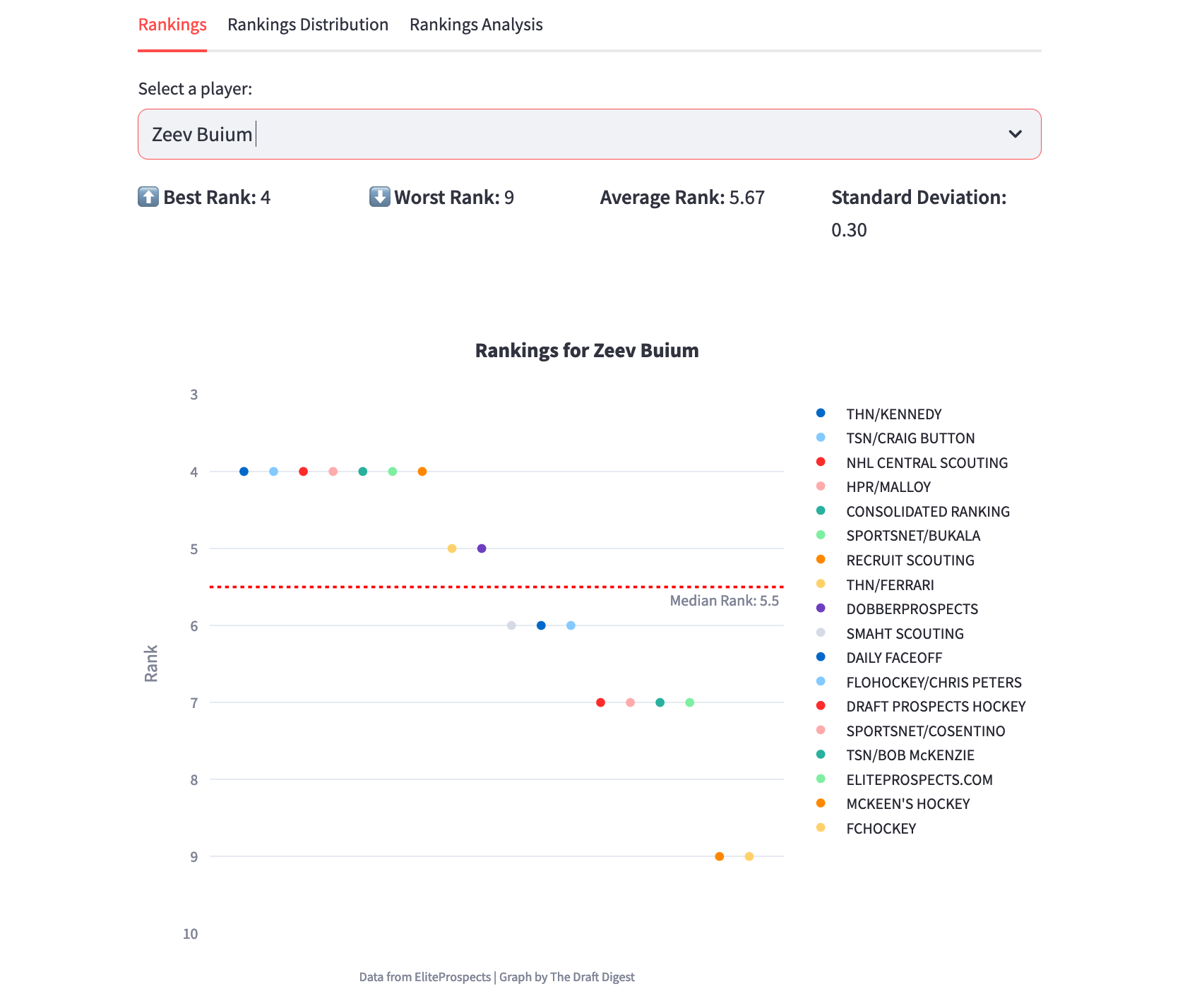
When I am writing those lines, there is a big feeling that Zeev Buium should be the #3 pick. EliteProspects’ API comes with an aggregator for public draft rankings. It comes handy when we want to see the level of consensus for the expected draft rank of a player. For non-math people, a standard deviation close to 0 means that most of the people agree on a draft rank while a higher standard deviation means that a player’s rank is more subject to debates.
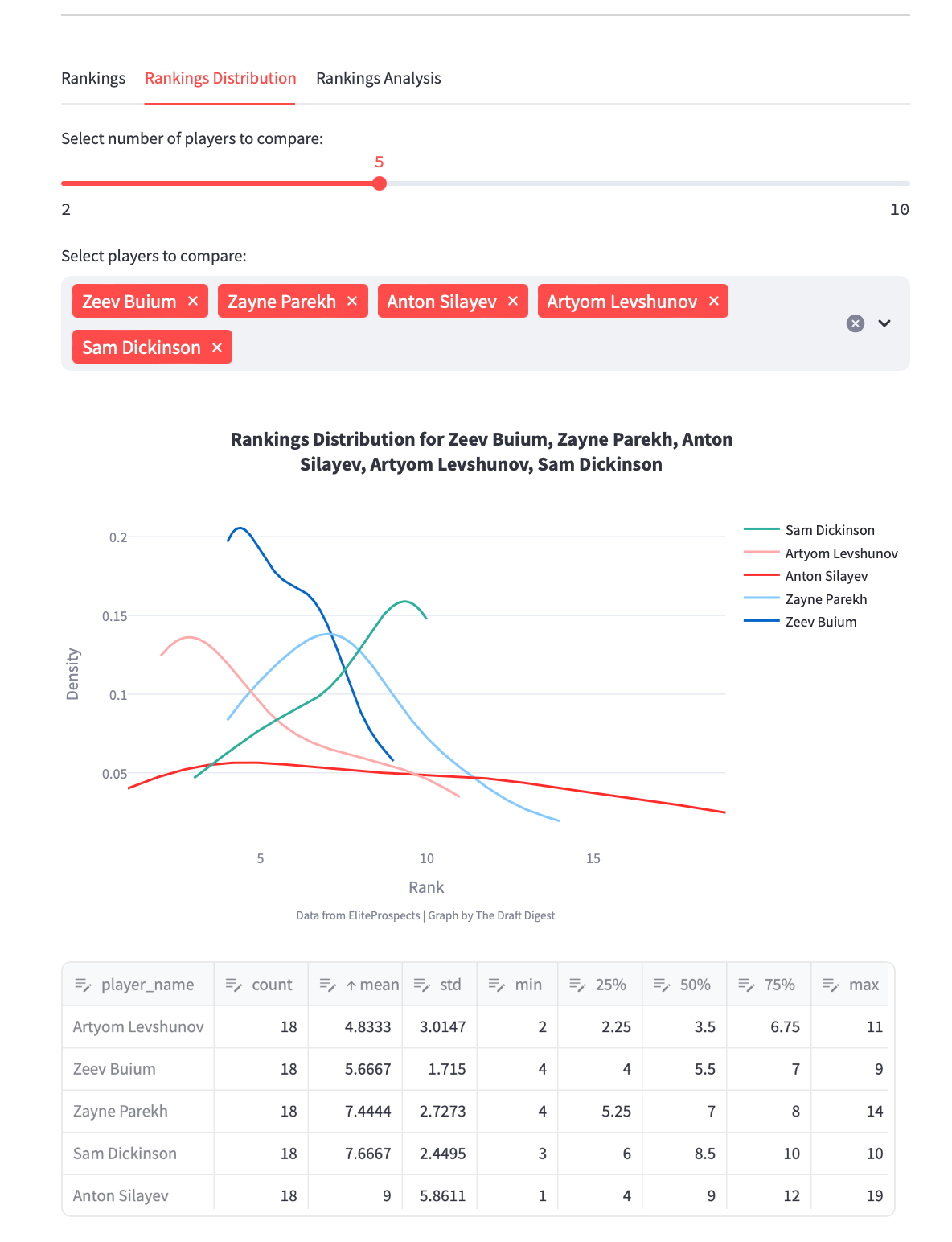
Who is the best defenseman of the draft? Apparently the draft is stacked with promising defensemen that should have their named called early. I arbitrarily selected 5 Ds that top the 2024 class and with this tool I could compare the distribution of draft rank. We also have an idea of some statistical informations about their ranking distribution. Comparing distribution helps us to see trends. We notice here that Levshunov seems to be leading the way while Silayev is the object of many debates in scouting rooms.
Player cards
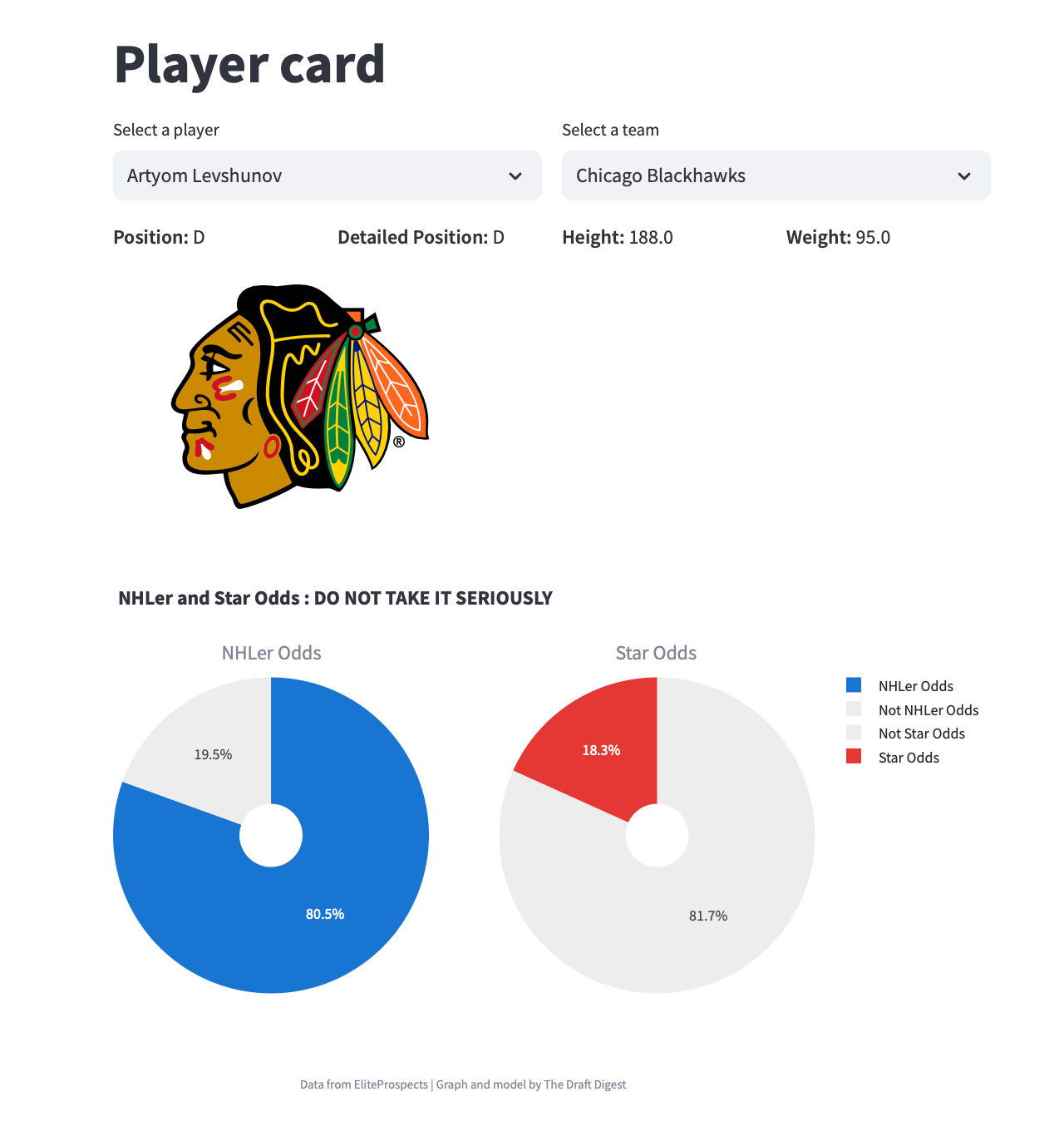
I think the most popular tools are the NHL and star model. They are also the ones I worked the least amount of time on. In 2 days, I built a tools that uses 80 variables to estimate the likelihood of a player becoming a NHLer or a star. To become a NHLer you need to have played at least 300 games in the NHL. My star % will be based on the odds that a Forward has 5 seasons in the 92.5th percentile or higher in PPG (so about 36 stars per season) or a Defenseman has 4 seasons in the 95th percentile or higher in PPG (for about 15 stars per season). So my datasets had the problem of being severely imbalanced. I also did not have the time to test other models and run parameter optimization (which could have helped to get better results). I also wished I took more time to run PCA on models. For the models, I am using the random forests algorithm. It is a popular classification algorithm for such tasks. “All models are bad (except for the one Chace built last year).” My model is bad. Really bad. So, don’t be surprised if it returns weird results.
Philosophizing the Draftology
My model has not been exposed to the same level of information that every single one of you got. It is really easy to say “Celebrini is the best prospect in the Draft” even if you have not watched him because throughout the year (and maybe even last year), you were exposed to some kind of consensus that Celebrini was the best player of the Draft. My model’s only variables are box score stats (points, goals, assists, +/-, PIM, all those stats relative to team and league, NHLe), handiness, age, and position. I think such models can be really useful (I am obviously biased, this is my bread and butter) when being made properly and used in the right conditions.
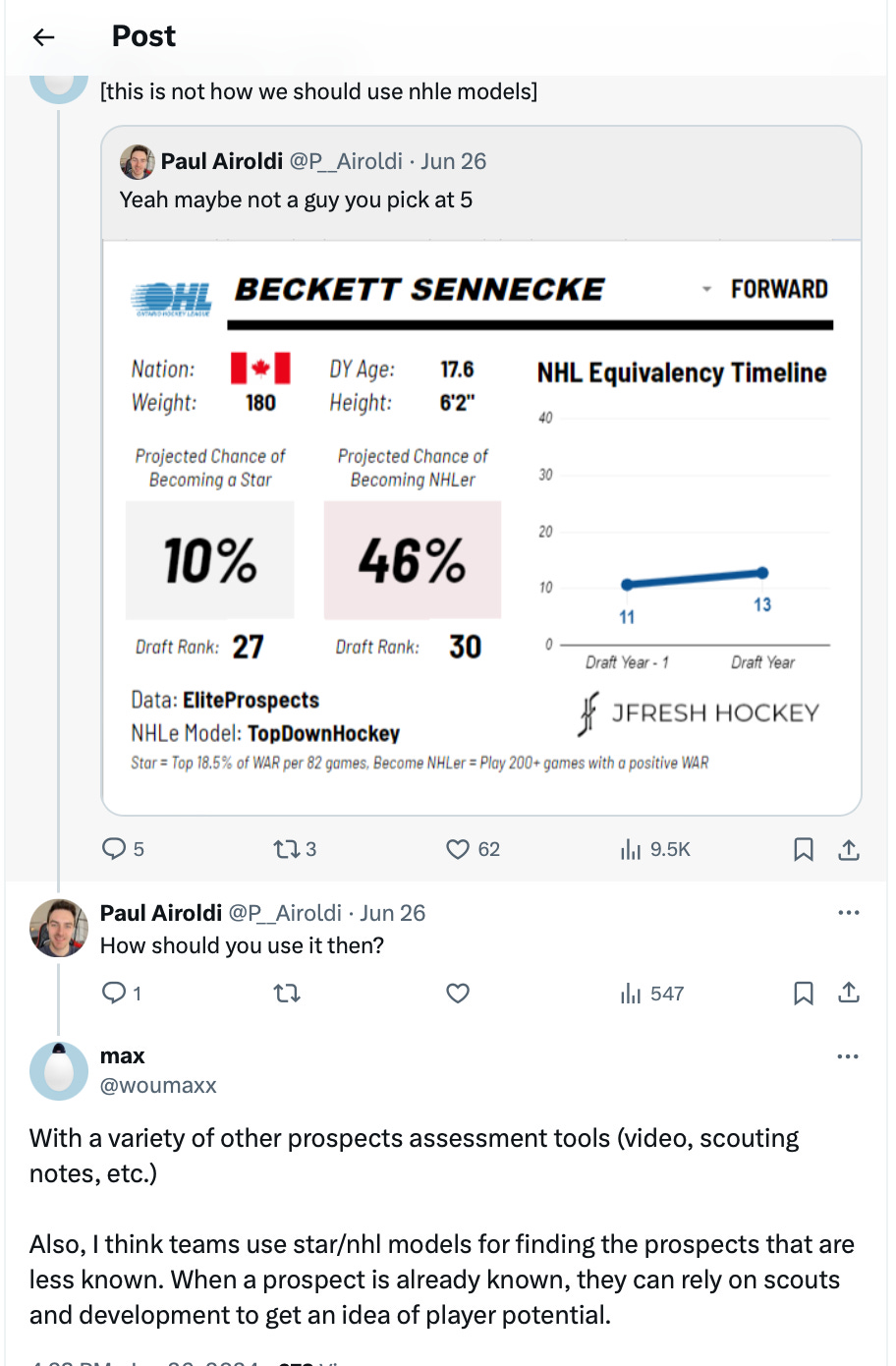
I think it is important to take a step back before using models and make conclusions using them. Some questions deserve to be answered before you start yapping around early conclusions.
Who made the model?
What algorithm was used?
What are the inputs?
What are the outputs?
Strengths of the model?
Weaknesses? Future improvements?
Why it was built?
How you evaluate the model?
In what context to use and to not use it?
On my end, I think my points equivalency method is good. Unfortunately, my star cutout might be too exclusive which makes the dataset too imbalanced and prone to bad results for the model. I also think my method is too unstable : a player NHLer/Star odds switch too much from a year to another. I also started to do that, but I want to reward more my model for finding stars. When you train such a model on a such imbalanced dataset, it is easy for the model to just say that everyone is a bust and get good scores at the end. The model think it is doing great because it will perform well in terms of “I am right more often than not”. But it is not really what you want. Finally, I think my workflow and the skeleton of my project is much better than it used to be which is promising for what I want to release next year with more time and more knowledge and experience.
When I started to use model, I was a young immature teen who did not really understand the math behind. It was fun to dunk on teams and players for “being bad” or making “horrible moves” because “the model said so”. With more experience behind my belt and more maturity, I understand why some hate data analytics in sports. I hate the person I was when I was making fun of players for having red spots in their players cards. Being in position to make real recommandations to real teams really thought me to things into perspective. We deal with real human beings and our recommandation lead to real moves. So what you do, what you say and how you say it has much more magnitude than how you can make tweet in a random afternoon. Data Analytics is really important in sports and I think the scientific process of approaching problems is the best way to solve business problems. But, unless you work for a data science product, the data science is only there to enhance the infrastructure that already exists. So do not think that all teams with a lot of analytics hire will only trade for players with blue player cards and will get rid of players with red players cards.
What is coming in the next couple of years will be massive. I think we are only seeing the tip of the iceberg in terms of how data science can have an impact on the draft and I am really excited to see how it will evolve. I am disappointed to not have a website ready for you today, don’t count me out yet : I am motivated to come back next year with an even better model, a website and more tools available for the public.
Have a good draft!